AIボイスレコーダー作った【M5Stack Atom Echo × Supabase × Gemini】
PlaudっていうAIボイスレコーダー、社内の一部のメンバーが使っているのだけど、私は使ったことがないんですよね。ちょっと羨ましい。ぶっちゃけスマホでええやんって思うんですが、やっぱ専用デバイスでボタンをぽちっとすればすぐに録音が始まるのは便利ですよね。特に録音なんてものは、サッとできてこそ。ということでAIボイスレコーダー(命名 Taroud)を作ったので、その話を書きます。
Ubieテックアドベントカレンダーの24日目のエントリーですが、アドカレというよりもハッカソン的なノリの内容で ネタ枠 です。
構成・全体像
スマホとは別の独立したデバイスを使おうということで、M5StackのAtom EchoというIoTマイコンを使います。Atom Echoの理由は、たまたま持っていたからです(オフィスに常設されている銅鑼が鳴らされたことを検知するために、以前、秋葉原で3,000円くらいで買ったものです)。Atom Echoは、ボタン、LED1個、マイク、スピーカーを持っており、Wifi接続が可能です。

実現したい体験は次のとおり。
シンプルですね。サッと録音を開始して、終了できる。終了したら勝手に要約が生成されるのもいいですね。
その他の登場人物
- Supabase
- Database: 録音のメタデータを保存
- Storage: 録音そのもの(wav)を保存
- Edge Functions: Geminiを叩いてSlackに通知する
- Gemini: 音声ファイルから要約を得る
- Slack: 要約完了の通知と、要約を見るためのインタフェース
最初は画面を作る気満々でしたが、バックグラウンドからの通知を実装するのが面倒だと思ったのでSlackをまるっと使うことにして、画面の作成を省略しました。
実現したい体験を絡めた、各登場人物のインタラクションは次のようになります。

記事を書くに際して、この絵をGeminiに投げて、シーケンス図を表現するMermaidを出力してもらいました(少し手を加えています)。

Atom Echo
2回目のボタン押下、すなわち会話・録音の終了の前に、WAV書き込みを行っています。この図では一度きりに見えますが、頻度高く何度も行います。これはAtom EchoのRAMの小ささからそのようにしています。
RAMやストレージが十分に大きければ、録音をたっぷり溜め込んだあと、一度だけアップロードすればOKです。しかし、実際にはそうはできません。Atom EchoのRAMは520KB、ストレージは4MB(プログラム領域を考慮するとWAVが保存できる領域はもっと少ない)。なので、録音したデータをAtom Echoに長く留めておくわけにはいかないのです。
今回の実装では、RAMに音声(8kHz。昔の固定電話と同じ)を保存しておき、2.9秒ごとにアップロードしています(3秒だと失敗することが多かった)。
最初、この高頻度のアップロードで、その度にconnect(SSLハンドシェイク等)が発生し、そのオーバーヘッドが録音の品質に悪影響を与えていました。とても聴けた音じゃない。ここは大いにハマりました。普段のプログラミングで意識することがありませんからね。1度確立したconnectionを再利用するようにしたら、言葉を識別できるレベルの音声になりました。
Backend
さくっとサーバーレスということでSupabaseを使うことにしました。FirebaseのREST APIを直叩きするのは、Atom Echoの素朴な環境で(あと慣れない言語で)使うにはちょっと大変そうだなと。
Backend as a Serviceをライトに使うだけなので、特筆することはないんですが、やってることを少しだけ説明します。
録音ステータスはDatabaseで管理し、実際の音声データ(細切れのWAV)はStorageに保存します。録音が終わると(2回目のボタン押下)録音ステータスをfinishedに書き換えます。すると、それをトリガーにEdge Functionsが呼び出されます。Edge Functionsでは、細切れのWAVを繋げて、1つのWAVにします。これを音声ファイルのまま(実際にはbase64)Geminiに投げて(今回はgemini-2.5-flashを利用)要約テキストを取得します。これをWebhookを使って、Slackに投稿する、という流れです。

細切れWAVを繋げて、1つのWAVにまとめる操作をバックエンドで行うのであれば、それを前提として、細切れWAVをヘッダー情報を持たないPCMにするということも検討しました。 Atom EchoのRAM節約にもなると思い、少し期待したのですが、一瞬で却下しました。 細切れWAV(一時的に溜めている音声データ)のサイズは46,400bytesなので、そのうちの44bytesを節約しても無視できるほどの効果です。 また、Storageにアップロードされた音声ファイルの品質をチェックするために、SupabaseのWebUI上で再生して確認するには、PCMではなくヘッダー情報を正しく持ったWAVである必要があったからです。
できたもの
Atom Echoはバッテリーを持っていないので、モバイルバッテリーなどと繋いで給電してやる必要があります。いざ、接続!

起動すると、Wifiに接続して、待機中である旨を示すLEDが青色に点灯します。ボタンを押すとLEDが赤色に変わり、録音が始まったことがわかります。5歳の娘とちょっとした雑談をしてボタンを押すと、再び待機中としてLEDが青に戻ります。数秒後、スマホにSlack通知が届き、要約が完成したことを知らせてくれます。

あとがき
実用性はない。
と思ったが、Atom Echoが3,000円で、Supabaseが無料で、Geminiが従量課金で駄菓子程度の費用ということを考えると、Plaudほどスマートな体験にはならないとはいえ、その代替としては検討しうるか。
ガチるならスマホアプリを作った方が断然いいですね。カメラアプリのシャッターを切るbluetoothボタン(電池入り)を使ってみると面白そう。500円くらいで手に入ります。シャッターを切る操作=音量上げキー押下なのでそれをバックグラウンドにいながらリッスンできたら、物理ボタンから一瞬で録音をスタートできて、やりたかったことに近づけます。
ということでAndroidアプリも作った
ボタンひとつで録音が開始するのが、やはり体験として最高だったので、どうしても実用的なものが欲しくなりました。
Androidであれば、 AccessibilityService を使ってボタン押下をグローバルに取得できます。
本来はその名のとおり、アクセシビリティを目的としたもので、アプリに対して強い権限を与えるので、目的外の使用ということでアプリストアで配布することはできないでしょう。
なので、あくまで自分用。

右手に持っているのが、カメラのシャッターを切るbluetoothボタンです。 これを押すと、どんなアプリが開いていようと、あるいは画面が閉じていようと、自分のアプリがそのイベントをキャッチしてくれます(そうなるように実装したということです)。 結果、録音がスタートします。画面上部に録音のnotificationが出現しているのがわかると思います。
話し終えた後、もう一度ボタンを押せば録音が停止します。 Wifi環境下では、録音を停止したあとに自動的に要約処理が走るようにしました。モバイルネットワークでは"ギガ"を節約するために何もしません(手動でも要約リクエストを投げられるようにしている)。

要約処理が完了すると通知されます。 通知をタップすると、その内容が確認できます。
なお、カメラのシャッターを切るbluetoothボタンは、一定時間(数分くらい?)ボタンが押されないとスマホから切断されます。 接続するにはボタンの長押しが必要です。 そのため、bluetoothボタンでサッと録音するのはあまり現実的ではないかも。 それでも、スマホの音量を上げる物理ボタンを押すこととイベントとしては同義なので、スマホのボタンをポチッとするだけという手軽さはあります。
Gemini 2.0の空間認識をJavaScriptで試す
Gemini 2.0 Flashのプレビューが出ましたね。 APIドキュメントを見て、興味を惹かれたのはBounding box detection。 かねてより、画像から対象の座標を取れたら面白いことできそうだな〜と思っていました。 Google AI Studioで試すことができます。

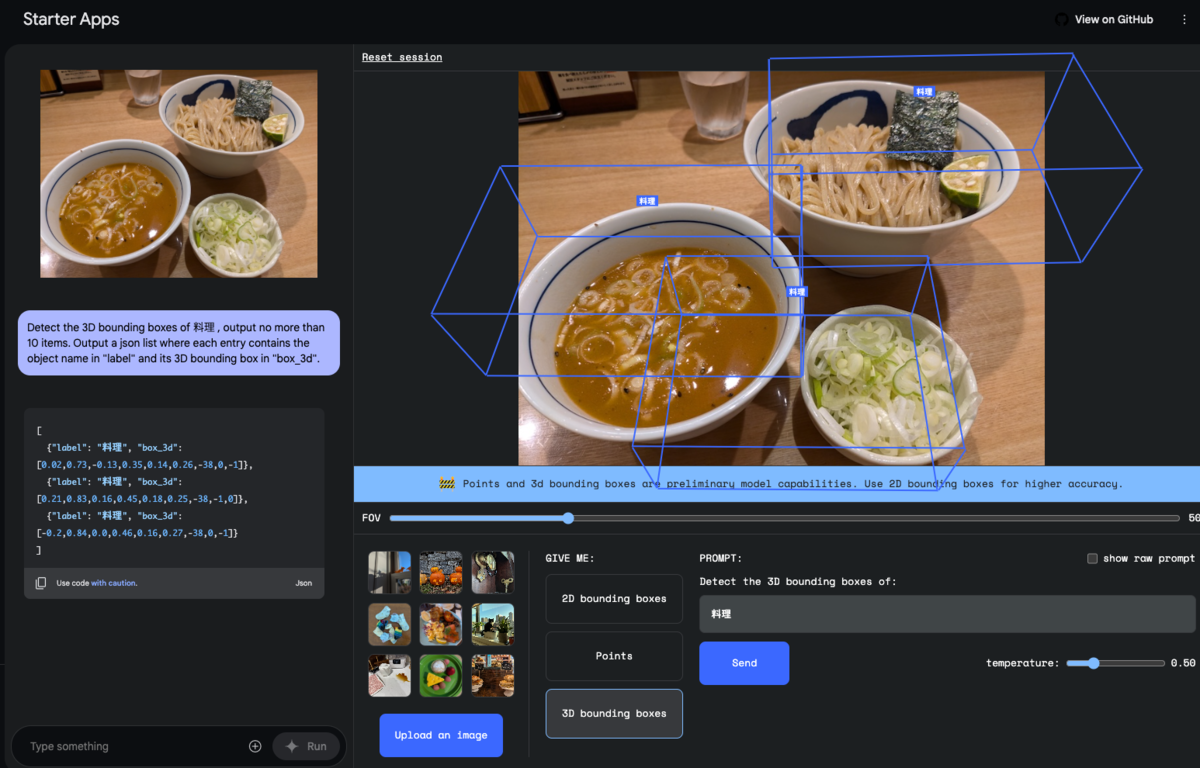
Google AI Studioが発行しているプロンプトを確認すると
Detect 料理, with no more than 20 items. Output a json list where each entry contains the 2D bounding box in "box_2d" and a text label in "label".
って感じで、自然言語でJSONの形式を指定しているんですね。OpenAIのstructured_outputに慣れているとちょっと驚き。 実際に、どういうレスポンスが来るのかは後述します。
この空間認識・バウンディング検出は、既存のJavaScript向けSDKでも利用可能であるのが、すぐ試すには手軽でよいです。 新しいSDKは、JavaScript向けの提供がまだ始まっていないようなので。
const model = vertexai.getGenerativeModel({ model: "gemini-2.0-flash-exp", });
素直に、新しいモデル名を指定するだけで使えるみたいです。
あとは、いつも通りに generateContent を呼び出してテキストを生成するだけです。
先述のようにバウンディングを検出したい旨をプロンプトに含めることで、決まった書式のJSONっぽいものが返されます。
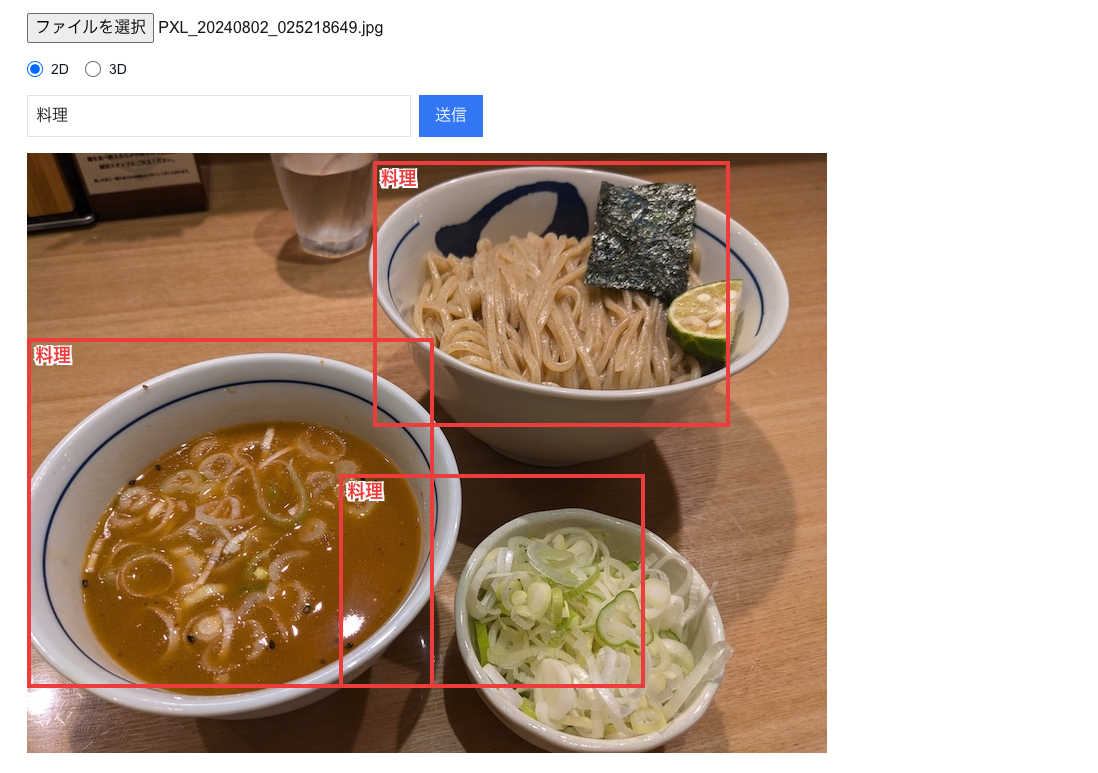
まずは2Dから実装。 プロンプトはGoogle AI Studioのものを、ちょこっといじってこんな感じにしてみます。
`Detect ${target}, with no more than 20 items. Output a json list where each entry contains the 2D bounding box in "box_2d" and name in "label".`
これでgenerateContentすると、次のようなテキストが生成されます。
```json [ {"box_2d": [13, 432, 457, 879], "label": "料理"}, {"box_2d": [309, 0, 892, 509], "label": "料理"}, {"box_2d": [535, 390, 892, 773], "label": "料理"} ] ```
純粋なJSONではなくて、JSONを含むMarkdownであることに注意が必要です。中身のJSONだけ取り出して扱いましょう。
整数の配列の意味はこの資料に書かれています。
画像 左上の座標を (0, 0) とし、右下の座標を (1000, 1000) としたときの、ボックスの左上、右下の座標を表しています。
y座標が先で、x座標が後なことに注意。
つまり [13, 432, 457, 879] は、左上 x=432, y=13 右下 x=879, y=457 です。
実際にブラウザ上にただ表示するのは簡単です。 CSSでabsoluteしてtop, left, width, heightを%指定するだけですね。
3Dも大体同じではあります。 Google AI Studioのプロンプトをいじって、こうしてみました。
`Detect the 3D bounding boxes of ${target} , output no more than 10 items. Output a json list where each entry contains the object name in "label" and its 3D bounding box in "box_3d".`
生成されるテキストはこんな感じです。
```json [ {"label": "料理", "box_3d": [0.41,1.54,0.22,0.71,0.74,0.87,-34,-13,10]}, {"label": "料理", "box_3d": [-0.31,1.55,-0.1,0.71,0.5,0.76,-34,-12,9]}, {"label": "料理", "box_3d": [0.06,1.54,-0.4,0.46,0.36,0.37,-33,-2,2]} ] ```
それぞれの数値の意味は
- 最初の3つ: x_center, y_center, z_center
- 真ん中の3つ: x_size, y_size, z_size
- 最後の3つ: x軸の回転、y軸の回転, z軸の回転(度数法)
で、ドキュメント曰く x_center とか x_size はメートル単位の長さっぽいです。 なので、画面に描画したあとはズームイン/ズームアウトを行って、元画像との重なりを調節しなきゃいけないと思います、たぶん。
今回はReactでThree.jsするReact Three Fiberを使いました。
ちなみに、Next.js 15系でReact Three Fiber 8.17.10だと、上手く動きませんでした。 このissueを参考に、9.0.0-rc.1 のReact Three Fiberを使ったら上手く行きました。
もう一つ厄介、というか誤解の種として、Three.jsの座標系とGeminiが返すそれは異なるので注意が必要です。 Three.jsは、画面に対して垂直方向がy軸で、奥行きがz軸。 Geminiは、垂直方向がz軸で、奥行きがy軸っぽいです。
そこを気をつけてReact Three Fiberで箱型の辺を組めば、期待通りに3Dを描画できます。
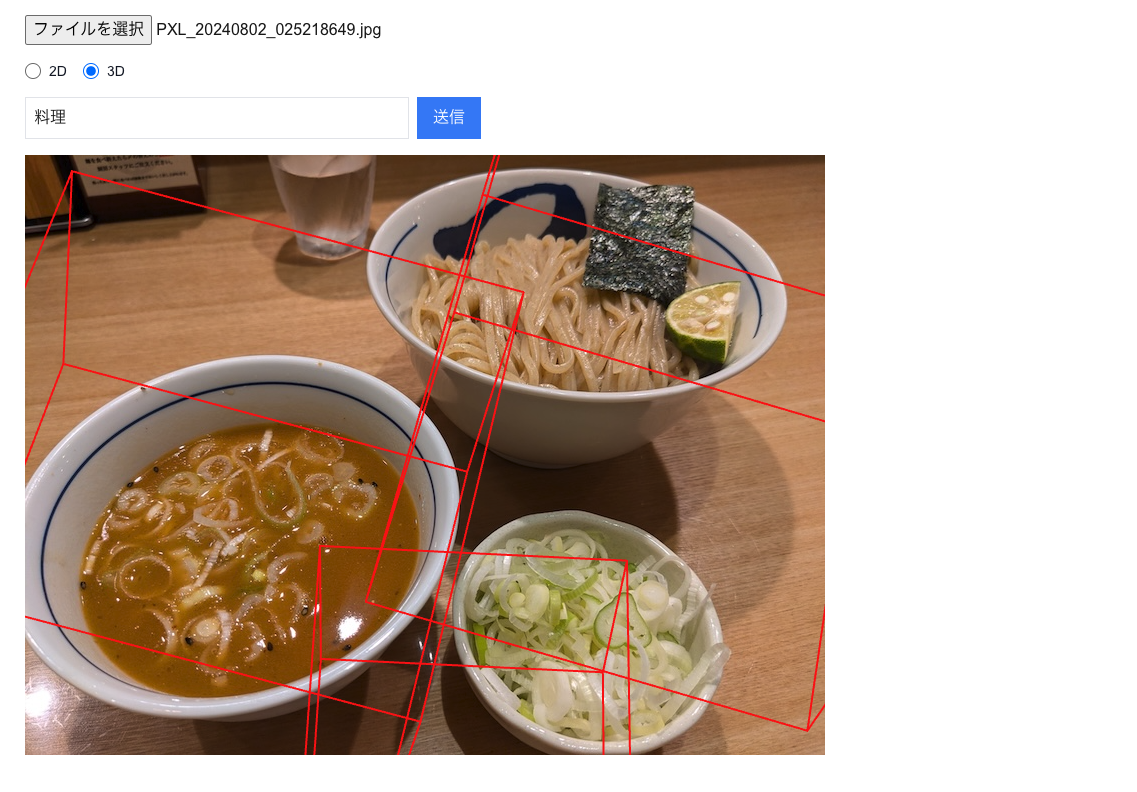
なお、3Dの方はまだ実験段階にあり、精度は高くないようです。
ところで、全然関係ないですが、使用している写真はつじ田、お気に入りのつけ麺屋さんの一つです。
Ubieだからこそプロダクト開発を全力で楽しめている
 この4月にUbie入社4年目を迎えました。
入社当初5, 6人しかいなかったメンバーも今では100人を超えました。
プロダクトも成長し、顧客も増えました。
入社から3年間で状況は様変わりしましたが、Ubie Discovery*1で働く本質的な楽しさは変わらないどころか、なんなら今が一番楽しいと思っています。
本エントリでは、この「楽しい」に集中できる理由と、そうしておけば万事良しの理由について話します。
この4月にUbie入社4年目を迎えました。
入社当初5, 6人しかいなかったメンバーも今では100人を超えました。
プロダクトも成長し、顧客も増えました。
入社から3年間で状況は様変わりしましたが、Ubie Discovery*1で働く本質的な楽しさは変わらないどころか、なんなら今が一番楽しいと思っています。
本エントリでは、この「楽しい」に集中できる理由と、そうしておけば万事良しの理由について話します。
*1:Ubieという会社は現時点でUbie DiscoveryとUbie Customer Scienceの2大組織で構成されており、僕やエンジニアなどが所属する組織がUbie Discoveryです。詳しくは「スタートアップで、カルチャーが全く違う2つの組織を作った話」をご覧ください。
いまさらだけどContentEditableをいじって、キャレットの扱いがしんどいということがわかったよ
WYSIWYGエディタに憧れてContentEditableをいじってみると、けっこうな底無し沼だと。気づいたときにはどっぷり浸かってるやつ。 ググればそれなりに知見が見つかるし、良い感じのライブラリもある。けど僕がやりたかったことは、自分でコードを書いて実現するのが早いんじゃないかなーと思って、沼にダイブした。
やりたいことは、ワープロソフトみたいなやつというよりも、編集しているテキストのスタイルがリアルタイムに変化するMarkdownエディタっぽいやつ。 つまりユーザがスタイルを当てるんじゃなくて、ユーザが入力したテキストに応じてスタイルを当てたい。 より正確には、テキストの見た目をおしゃれにするだけではなくて、もっと高度な何か、Reactのコンポーネントとか、を埋め込むとかしたかった。

Draft.jsやEditor.jsのような、ContentEditableを扱いやすくしてくれるライブラリも検討した。
Reactのコンポーネントを埋め込むのも簡単そうだった。
ただ、ContentEditableの内容を入力のたびに再構築するような方法を採ると、キャレット(エディタ内にあるテキストが挿入される箇所を示す | これ)が編集箇所とは無関係に先頭とかに飛んでしまう現象があった。
パフォーマンス上の懸念はありつつも、ContentEditableの内容を再構築する方法は、ユーザの入力内容を解析してUIに反映する上で一番楽な方法だと思ったので、これを譲りたくなかった。
かくしてやめときゃいいのに素のContentEditableをいじることとなった。