いまさらだけどContentEditableをいじって、キャレットの扱いがしんどいということがわかったよ
WYSIWYGエディタに憧れてContentEditableをいじってみると、けっこうな底無し沼だと。気づいたときにはどっぷり浸かってるやつ。 ググればそれなりに知見が見つかるし、良い感じのライブラリもある。けど僕がやりたかったことは、自分でコードを書いて実現するのが早いんじゃないかなーと思って、沼にダイブした。
やりたいことは、ワープロソフトみたいなやつというよりも、編集しているテキストのスタイルがリアルタイムに変化するMarkdownエディタっぽいやつ。 つまりユーザがスタイルを当てるんじゃなくて、ユーザが入力したテキストに応じてスタイルを当てたい。 より正確には、テキストの見た目をおしゃれにするだけではなくて、もっと高度な何か、Reactのコンポーネントとか、を埋め込むとかしたかった。

Draft.jsやEditor.jsのような、ContentEditableを扱いやすくしてくれるライブラリも検討した。
Reactのコンポーネントを埋め込むのも簡単そうだった。
ただ、ContentEditableの内容を入力のたびに再構築するような方法を採ると、キャレット(エディタ内にあるテキストが挿入される箇所を示す | これ)が編集箇所とは無関係に先頭とかに飛んでしまう現象があった。
パフォーマンス上の懸念はありつつも、ContentEditableの内容を再構築する方法は、ユーザの入力内容を解析してUIに反映する上で一番楽な方法だと思ったので、これを譲りたくなかった。
かくしてやめときゃいいのに素のContentEditableをいじることとなった。

結論としては「キャレットを制す者はContentEditableを制す」だ。 出力したいUI次第だけどキャレットを良い感じに扱えれば、あとは些細な問題でちょっとしたテクニックでどうにでもなる。 雑に列挙するとこんな感じ。
- ContentEditableにおけるキャレットの位置を知るためには
document.getSelection()などでSelectionを得て、そのfocusNode,focusOffsetなどを使う。 - 例えばContentEditableな要素が持つ最初の子要素から
focusNodeが見つかるまで「文字数」をカウントしていき、focusOffsetを足したり引いたりして調整すれば、そこがキャレットの位置となる。 - 「文字数」は「何を1文字とするか」を自分のロジックの中に記述していくことになるけど、これはどういうUI(DOM)にしたいか次第(これが相当しんどいのです)。
- ContentEditableでキャレットを指定の位置に移動させるには、同じようにSelectionを使う。
selection.addRange(range)で、指定の位置に設定したRangeを渡せばOK - Rangeには「どの要素」の「何文字目」かを指定する必要があって、それを導出するために、先ほどのキャレットの位置=カウントした文字数を利用する。
- ContentEditableな要素が持つ最初の子要素から順に走査して、指定文字数に達したときの要素が、Rangeに設定すべき要素となる(が、要件次第で全然変わる)
以下、蛇足。
単純なセットアップでは、期待どおりに挙動しない
次のコードは、ContentEditableを実験するReactコンポーネントとしては完全なコード。 その実行結果も下の枠の中で確認できるので、何かテキストを入力してもらいたい。
セクション見出しにも書いてあるけど、期待どおりに挙動しない。 連続してキーを叩いて単語を入力しようとしても、キャレットが先頭から動かず「hello」と入力したつもりがその逆順「olleh」になってしまう。

onInputで入力イベントを受けて innerHTML をuseStateのhtmlとして保存する。次の描画時に保存された html がContentEditableな要素にセットされるという単純な寸法ではダメっぽい。
入力時にキャレット位置を記憶し、画面反映後にキャレット位置を復元する
雑に列挙したキャレットの扱い方のとおり、入力時にキャレット位置を記憶し、画面反映後にキャレット位置を復元すれば、連続してキーを叩いて目的の単語を入力することが可能になる。

上記は完全なコードなので、例示するコードとしてはノイジーだけど細かいロジックは無視してかまわない。
キャレット位置特定と、指定位置へのキャレット移動に関するヒントにはなりえるけど、散々言っているとおり要件次第でロジックも変わるので、まるっと参考にできるものではない。
ここでは現在のキャレット位置を取得する関数をgetCaretPosition、指定の位置へキャレットを移動する関数をmoveCaretという名前にしている。
それらの定義を省いてコンポーネントだけにしたのが、次のコード。
export const Example2: FC = () => { const editorRef = useRef<HTMLDivElement>(null); const [html, setHtml] = useState(""); const [caretPosition, setCaretPosition] = useState(0); useEffect(() => { const editor = editorRef.current; if (editor == null) return; moveCaret(editor, caretPosition); }, [html]); const onInput = (e: FormEvent<HTMLDivElement>) => { const currentHtml = e.currentTarget.innerHTML; setHtml(currentHtml); setCaretPosition(getCaretPosition(e.currentTarget)); }; return ( <div> <div ref={editorRef} contentEditable onInput={onInput} dangerouslySetInnerHTML={{ __html: html }} /> </div> ); };
onInputで入力内容を保存するとともに、getCaretPositionを呼び出してその値を保存する。
入力内容(html)に反応するuseEffectの中でmoveCaretを呼び出して、先ほど保存したキャレット位置とContentEditable要素(editor)を引数としている。
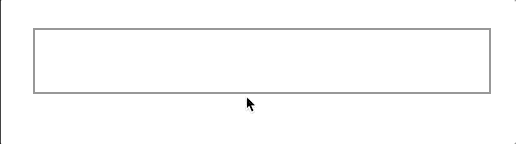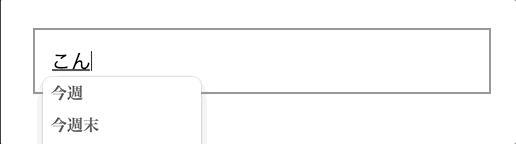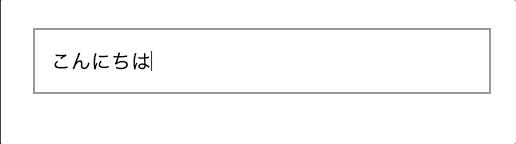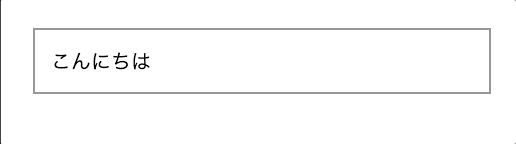
「hello」と打てば「hello」と入力されるので一旦成功だけど、実は日本語の入力がおかしくなる。 「こんにちは」と入力しようとすると「kおnnnいtいhあ」と入力されてしまう。

日本語入力に対応する
onInputにより入力したそばから、その内容が描画されるので、ローマ入力や漢字変換の暇を与えてくれないのが原因っぽい。
ということで、入力が確定されるまで画面に反映しないようにしたのが、次のコード。
英字でも日本語でもカウントされる文字数や要素に変化があるわけではないのでgetCaretPositionとmoveCaretはそのまま。
変更点はinputHtmlとisInputtingという状態を追加したこと。
inputHtmlは入力された内容をバッファーする。htmlに内容を書き込むまでは画面に反映されない。
isInputtingは入力中、つまり入力が確定されていないときにtrueとなるフラグ。
useEffect(() => { if (isInputting || intputHtml == null) return; setHtml(intputHtml); setInputHtml(undefined); }, [isInputting, intputHtml]); const onInput = (e: FormEvent<HTMLDivElement>) => { const currentHtml = e.currentTarget.innerHTML; setInputHtml(currentHtml); setCaretPosition(getCaretPosition(e.currentTarget)); };
このようにonInputで入力された内容を一旦inputHtmlに退避させて、入力中でないタイミングでinputHtmlの内容をhtmlに書き込む。その後、inputHtmlにはundefinedでも入れておいてバッファーをフラッシュする。
入力状態については onCompositionStart と onCompositionEnd でイベントを拾う。
ローマ字入力や漢字変換などが始まったタイミングで前者が、それが終わったタイミングで後者が呼び出される。
<div ref={editorRef} contentEditable onInput={onInput} dangerouslySetInnerHTML={{ __html: html }} onCompositionStart={setInputting.bind(null, true)} onCompositionEnd={setInputting.bind(null, false)} />
Reactコンポーネントを埋め込む
ここまでできたら、あとはContentEditableに何を含めるか、どうキャレットを計算するか、という話に尽きる。
ちょっとガバガバだけど、入力内容に応じてReactコンポーネントをContentEditableに埋め込むやつが次のコード。
[hoge] みたいに入力すると、ラベルっぽくなる。
[hoge] なラベルは、テキストとしては6文字だけど、編集不可能(contenteditable="false")にしてこれを1文字としてカウントしたい。
なので getCaretPositionとmoveCaretのロジックを変更する必要がある。
例えばキャレット位置を計算するときに要素を再帰的に走査するけど、contenteditable="false"のような特定の要素を見つけた時に1文字カウントして、その子要素はスキップするなどのロジックを追加する。
Reactコンポーネントを埋め込むためには、まずプレースホルダーというか、その埋め込むべき場所を示す要素をぶちこむ。
抜粋した下のコードは、入力された内容を描画用HTMLに変換する関数で<span contenteditable="false" class="label" data-text="${block.text}"></span>が、Reactコンポーネントを埋め込むための要素となる。
コンポーネントにpropsとして渡すためのデータを要素の属性に載せておくなどの工夫をしている。
const toHtml = (text: string): string => { const blocks = parse(text); return blocks .map((block) => { if (block.type === "normal") { return `<span>${block.text}</span>`; } return `<span contenteditable="false" class="label" data-text="${block.text}"></span>`; }) .join(""); };
描画用HTMLの変更を検知して、すなわちuseEffectの中で次のコードを実行することで、先ほどのプレースホルダーにReactコンポーネントが埋め込まれる。
document.querySelectorAll(".label").forEach((label) => { const text = label.getAttribute("data-text"); render(<Label>{text}</Label>, label); });
まとめ
